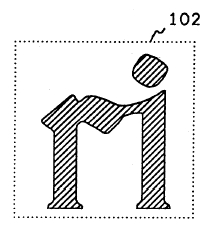
Dark image joins adjacent letters
Please post all comments on tesseract's sourceforge.net forums and be sure to specify the version of the docs: V0.03!
In short, a DAWG is a very compact way of storing data that has a great deal of repetition and which, unlike more familar algorithms for compression such as ZIP/GZIP, permits direct and fast scanning.
Tesseract uses two DAWGs, one to store the built-in list of words (dictionary) and another to store the user's list of words, when checking the various combinations of letters in werds it has recognized, in its attempt to improve the accuracy.
In version 1.02, two dictionaries can be found in the 'tessdata' directory:
NW N NE
\ /
W + E
/ \
SW S SE
"Edge detection" finds changes (flips in the [binary] pixels) in each row. When these are "stacked" (by referencing the previous line(s)), cracks can be extracted. If/when these cracks "join" at some point, after some lines, they are approximated into outlines. Then, [a lot happens you never see] and these get eventually fed to the matcher...
I thought about "making up" an example but it was actually faster and conducive to my hacking [1] to trace the real thing.
e===================================================== e===================================================== e===================================================== e===================================================== e===DEEEEEEED=============DEEEED===============DEED=====DED=== e===K=DEEEEEC==========DEEJEEEHED=============K=K===DEJC== e===K=K==============DECDEC===LD=LD============LD=LD==DEJC=== e===K=K=============DECDEC=====LD=LD============LD=LD=KK==== e===K=K=============K=K=======K=K============LD=LJC==== e===K=LEEED==========K=K=======K=K=============K=K===== e===K=DEEEEC=========K=K=======K=K============DEJD=K===== e===K=K=============K=LD=======KDEC============KKKLD===== e===K=K=============LD==K=====DECK============DEJCLD=LD==== e===K=K==============LD=LD====DEJEC===========DEJC==LD=K=== e===K=K===============LD=LEEEJC============DECK====KLD=== e===LEC================LEEEEC=============LEC====LEC== e=====================================================
But first, we need to be clear on one concept handy in edge-detection.
line_edges() is actually doing something that can be conceptualized as XOR/derivative - it's really after ONLY change. You should be able to understand exactly what I'm saying when you see what happens when the 'O' is filled in with solid black color using gimp (actual result, not simulated):
e================= e====DEEEEED====== e===DEC====LD===== e==DEC======LED=== e=DEC=========K=== e=K==========LD=== e=K===========K=== e=K===========K=== e=K===========K=== e=LD==========DEC= e==LD========DEC== e===LED====DEEC=== e=====LEEEC======= e=================
line_edges() still managed to find JUST the edges - the "unchanging" fill just disappeared. (For the observant, there's only 'one' edge while the previous "O" had two; it's not recognized as an "O" while the above WAS...)
Since even the tiny image of "FOX" is a bit big, let's just focus on the leading corner of the 'F' - we'll explain the meaning of the letters (and numbers) as we go along. By the way, if you're only interested in a summary, skip ahead to 'big picture'.
e============== e===DEEEEEEED== e===K=DEEEEEC== e===K=K======== e===K=K======== e===K=K========
The first line starts with an 'e' because line_edges() was called. The subsequent '='s indicate that the previous line had no cracks and the color at each x position has not changed from the previous (x-1) and has not changed from the same x on the previous line (y-1) - line_edges() is bored.
On the second row, the 'D' indicates that the previous line is empty but that the current x's color changed from that of the previous pixel (x-1). 'D' also means that v_edge() got called. To better see what v_edge() and h_edge() are up to, let's quickly rebuild with -DTV_FOCUSC and -DTV_FOCUSD.
Our image becomes notably 'noisy':
e========================================== e===kmnDbcgEbcgEbcgEbcgEbcgEbcgEbcgEkloD=== e===kmpK=klnDbdhEbdhEbdhEbdhEbdhEC========= e===kmpK=kloK============================== e===kmpK=bcgLbcgEbcgEbcgEkloD============== e===kmpK=klnDbdhEbdhEbdhEbdhEC============= e===kmpK=kloK============================== e===bdhLbdhEC============================== e==========================================
The first 'D' means that the previous line is empty but that the current x's color changed from that of the previous pixel (x-1) and is output after v_edge() is called: started a new vertical crack ('k'); the sign [2] <= 0 ('m'); and there's nothing to join ('n'). (Incidentally, look on the 3rd row directly under the 'n' - there's a 'p' in its place meaning that on THAT row there WAS an edge in progress... the one that just now was started.
After the 'D', the 'E' means that color at 'x' changed from that at the same 'x' on previous line (y-1) - is output after h_edge() is called: started a new crack ('b'); the sign > 0 ('c'); and that an edge (here started by 'n') is continuing ('g'). (No 'j' printed because free_cracks is shared by v_edge & h_edge and that job was done by 'n').
Rest of the row is boring until the last 'D' which means the same thing it did before - the same x on the previous line (y-1) was different. What's key is that v_edge() now decides to: start a new vertical crack ('k'); the sign > 0; and there was a [fake'] edge to join to (we've been tracing the horizontal edge of something & it has come to an end so that 'end' is the vertical edge).
Of course, line_edges() keeps as many edges in progress as necessary. Three vertical lines (two on the sides and one in the middle) will look like this:
e========= ekmnDbcgEkloD===kmnDbcgEkloD===kmnDbcgEkloN ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ekmpKkloK==kmpKkloK==kmpKkloO ebdhLC==adhLC==adhLM e=========
===== BIG PICTURE =====
line_edges() works scanline by scanline looking for CHANGES in color. When it finds these changes, it creates and tracks both vertical and horizontal edges:
e.g., a horizontal, one-pixel-width line has BOTH: at the start there's a vertical edge, during the run of its length there are two horizontal edges, and at the end there's a final vertical edge.
In each successive scanline, edges are detected and cracks followed until TWO cracks meet [3] (forming a loop). Then, this list of points - now called an "outline" - is sent in for "cleaning and approximation" by complete_edge() and the list of edges is freed.
while callpicofeat() is called, it's from a somewhat unexpected place
========= Q&A =================
[1] My hacking revolves around removing/supressing noise in FAXes which is manifest as continous, 'vertical' streaks throughout the image at one or more x locations. This noise is disasterous to recognition and also, alas, chews a lot of CPU. I've had some success in eliminating the streaks by adding an additional state machine (very similar to line_edges()) that looks for these streaks. When these are confirmed (i.e., start below the header, last through the whole image & satisfy some other thresholds), they can be dealt with.
These streaks are much simpler to deal with than, for example, scans from ruled/lined paper because they are EXACTLY PARALLEL to the Y axis (they are caused by white-out/crud on the glass inside the FAX machine so fixed in location). And, all the pages FAXed on such machine have streaks in EXACTLY the same x positions, so that only the first page requires careful analysis.
[2] sign is just a way of keeping track of what the color chaged FROM. The sign > 0 on transition from edge to background (black-->white) and < 0 vice verse (white-->black).
The pre-release of tesseract used to have the file "DangAmbigs" which contained the following: "m rn", "rn m", "m in", "in m", "d cl", "cl d", "nn rm", "rm nn", "n ri", "ri n", "li h", "ii u", "ii n", "ni m", "iii m", "ll H", "I-I H", "vv w", "VV W", "t f", "f t", "a o", "o a", "e c", and "c e"
To my knowledge, only 'I1l' and 'm' receive special treatment in tesseract because the Context and DAWG (see the respective section) are used to increase the accuracy.
There are several types of 'features' & it is best to keep them distinct:
Let's compare gocr's definition of a feature with tesseract. Here's what gocr (v0.39) gives in its own docs (BTW, I'm not "picking on" gocr - it just happens of have clear documentation on what & how it approaches the same problem).
vvvv vv- white regions
......@@...... <- crossing one line
......@@......
.....@@@@.....
.....@@@@.....
.....@@@@.....
....@..@@@.... <- white hole / crossing two lines
....@..@@@.... <- crossing two lines
....@..@@@....
...@....@@@...
...@....@@@...
...@....@@@...
..@@@@@@@@@@.. <- horizontal line near center
..@......@@@..
..@......@@@..
.@........@@@. v- increasing width of pattern
.@........@@@. v
.@........@@@. v
@@@......@@@@@
^^^-- gap
"In the future, the program should detect edges, vertices, gaps, angles
and so on. This is called feature extraction (as far as I know)."
Other OCR programs, like gocr, attempt to extract high level features of each character and classify the character based on those features. If the characters on the page are of a high quality, such as an original typed page, these simple processing methods will work well for the process of converting the characters.
However, as document quality degrades, such as through multiple generations of photocopies, carbon copies, facsimile transmission, or in other ways, the characters on a page become distorted causing simple processing methods to make errors.
For example, a dark photocopy may join two characters together (like the "r" and "i", below), causing difficulty in separating these characters for the OCR processing. Joined characters can easily cause the process that segments characters to fail, since any method which depends on a "gap" between characters cannot easily distinguish characters that are joined.
Dark image joins adjacent letters
Light photocopies produce the opposite effect. Characters can become broken, and appear as two characters, such as the character "u" being broken in the bottom middle to create two characters (below), each of which may look like the "i" character. Also, characters such as the letter "e" may have a segment broken to cause them to resemble the character "c".

Light image breaks letters
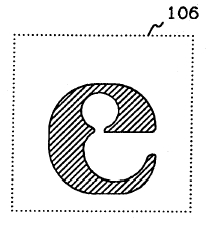
Light image breaks closures
Programs like gocr begin by extracting higher level features from each character image in an attempt to select a set of features which would be insensitive to unimportant differences, such as size, skew, presence of serifs, etc., while still being sensitive to the important differences that distinguish between different types of characters.
High level features, however, can be very sensitive to certain forms of character distortion, as demonstrated above. That is, a simple break in a character can easily cause a closure to DISAPPEAR, and the feature extractor method that depends on such closures would probably classify the character incorrectly.
Often the high level feature representation of a character contains few such features. Therefore, when a single feature is destroyed, the classification (differentiation from other characters) is negatively impacted.
Tesseract takes a completely different approach, even if one much more complicated. (this is a high-level decription, as per the patent - a LOT happens inside tesseract before your image gets to the stage where features are recognized)
Note: due to the way in which edge-detection works, characters that are open (have no closures) like C, T, V, etc. have only ONE outline (the outer one). On the other hand, characters like O, P, A, have one closure and characters like B actually have two. See "Edge Detection" for the gory details.
.......1......
......@@......
.....2@@......
.....@ii@.....
.....@ii@.....
.....@ii@18...
....@..@i@....
...2@..@i@....
....@..@i@....
...@....@i@...
...@....@i@17.
...@.....i@...--------> 0 degrees (due East)
.3@@@@@@@@i@..
..@9.1011@i@16
..@......@i@..
.@8.......@i@.
4@......12@i@.
.@........@i@.
5@@@7...13@@@@@15
6 14
Looking at the above picture, start at "1" and go Counter-Clock Wise (CCW):
That is precisely why tesseract is insensitive to character segmentation boundaries. These features also have a low enough level to be insensitive to common noise distortions and sufficient number of features are created that some will remain to allow character classification even if others are destroyed by noise. Finally, these features are a lot less sensitive to font variations than many other matching techniques.
With that said, there are several problems. First, tesseract needs to be very carefully trained before any additional letter can be recognized. This is why languages other than English are currently not supported (as of version 1.02). Second, these trained features must be stored somewhere. This means that unless they are somehow incorporated into the executable (which has its own problems), they must be stored in a file. In version 1.02 that file is in tessdata directory and is called "inttemp" (a bit over 600KB). Third,
I'm not done with this section!
==================
FIX: A character can be made of several blobs but, intially, features are extracted from single blobs. Up to MAX_NUM_INT_FEATURES (defined as 512 in classify/intproto.h) can be extracted from a character.
==================
FIX: The pre-trained templates (See Prototype) are sufficiently 'smeared' (by SmearBulges() in classify/mfx.cpp) to comfortably match different fonts representing any particular character.
FIX: this is not finished. But it's better than it was before :-)
The map is held as an array of counts of rows which have a wide gap covering that region of the row. Each bucket in the map represents a width of about half an xheight - (The median of the xhts in the rows is used.)
The block is considered RECTANGULAR - delimited by the left and right extremes of the rows in the block. However, ONLY wide gaps WITHIN a row are counted. (definition moved from gap_map.cpp)
In fact, if you look at the .raw file from the testing/image_courR18.tif, you will see that ALL 'i's come out as '1's while this does not happen with testing/image_2helvR18.tif (.raw files are not output by v1.03)
Does this mean that the feature extractor should have a set of templates for different font families? I know the dictionary and word-heuristics certainly help (after all the .txt file is almost right) but this seems to indicate a serious shortcoming.
As an example of my comment above, 'Bristol' is not in the dictionary so the '1' in .raw gets turned into a 'l' by the word-heuristics, not the 'i' that it should have been. Ie: there is only so much rules can do and it's always better to improve the .raw output.
If you look at the .raw file from the testing/image_courR18.tif, you will see that ALL 'o's come out as '0's while this does not happen with testing/image_2helvR18.tif. See the entry for 'I1l' for more info.
It would be most helpful if Ray Smith could look this list over and point out dumb mistakes. Our deeper understanding of what's going on depends on this.
However, sometimes the letter with the highest certainty may not be the correct letter by applying certain heuristics (i.e, a word generally doesn't have a number in the middle of it, so the '1' (one) is changed to an 'l' (L), etc.)
After these heuristics are applied, tesseract sends the word to the permuter which is a function that exchanges less-certain letters in each position and then checks whether that PARTICULAR combination of letters matches directly in DAWG/dictionary. Every (??) word is permuted in this manner in the hope that at least one of these directly matches the dictionary.
See entry for DAWG and permute.cpp
The included file 'tessdata/inttemp' contains built-in/pre-trained prototypes for all ASCII characters for a dozen or more different fonts.
Ray Smith has released the code (training/training.cpp) used to generate this (tessdata/inttemp) file but we do not yet know how to a) make the training image(s), b) do the adapting, c) work the training code.
?? Used in approximating the outline - converting a 'shape' from a list/series of coordinate-pairs (in one coordinate system) into a 'formula' (in any coordinate system). ?? A, B, C are coefficients of the quadratic ?? Making each feature a quadratic, of sorts ??
You might be interested in the raw file when fiddling with the feature extractor and accuracy of tesseract PRIOR to DAWG/dictionary.
See ExtractIntFeat() in classify/intfx.cpp
Read more about it on http://en.wikipedia.org/wiki/Radius_of_gyration
THE END THE END THE END THE END THE END THE END THE END THE END THE END
 1.5.1
1.5.1